Welcome to our second bias deep-dive at Wordnerds. Last time, we spoke about how bias can infiltrate every part of our society, even the glitter-strewn innocence of Strictly. Now we're going to tell you about how this bias can infiltrate the world of AI, and cause significant problems.
First, a really quick overview of how AI works. To be clear - this is so simplistic it’s the equivalent of re-enacting the moon landing by throwing a milk bottle at a patio. We’re leaving out a lot of the detail. Depending on your definition, AI could cover everything from pocket calculators to self-driving cars, but in this context it’s a computer programme that learns from the data we give it, finds patterns we couldn’t spot, and uses them to solve problems that we currently give to human brains.
Take, for example, the AI problem that keeps us up at night - teaching a computer to understand language. First of all, you need to show it language. A lot of language. Millions upon millions of sentences. The self-learning algorithms will find patterns in these sentences, learning the contexts in which words are mostly used, what words are used in similar contexts, and how the meaning changes within a sentence.
Once the AI has this base level of understanding, the only limit is the problem we want to point it at. From chatbots to legal discovery to national security, people are able to create all kinds of wonderful things.
At Wordnerds, we use these huge neural networks to allow our customers to automatically categorise their text data based on their exact needs.
So what’s the problem? Well, as I said, these neural networks require millions of sentences to train them in our language. And there’s only one place where you can get millions of sentences. Human beings.

Our yikes moment
So the big neural networks are all made up of individual sentences written by people, mostly from things like Wikipedia, IMDB and social media. And as we saw from the vagaries of the Strictly vote, if there’s a slight bias in the dataset, it can be writ large upon the outcomes.
The watershed moment for us was when we were playing with RoBERTa (a large language model made by Facebook). This tool allows you to give it a sentence with a word mask and it will suggest the most likely words to fit into that space. If you’ll forgive the technical jargon, we’ve essentially taught a robot to play Blankety Blank.
Here are its suggestions for the sentence “I took a <blank> to work”. The numbers underneath are how sure it is on each guess.

The amazing thing about this technology is that it isn’t supervised in any way. Nobody’s told it to look for modes of transportation - it’s figured this out based entirely on its understanding of language.

But its understanding of language is based on how people used language in the first place. And that can lead it to some scary opinions.
To demonstrate this, we asked this model to give us its suggestions for the sentence “[name] likes playing with <blank>”, swapping in different names to see how its guesses changed.
Here’s what it came up with for “John”.

Computers and robots: very fine leisure pursuits. But look what happens to the AI’s guesses when we switch to a female name.
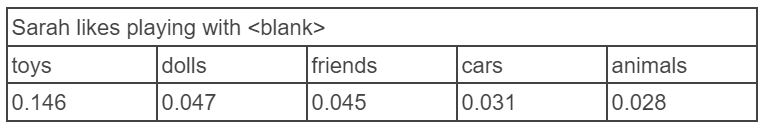
Just to recap - an AI has looked at the way we use language, and now believes that John likes playing with computers and Sarah likes playing with dolls.
And it gets much, much worse.
This is what happens when we ask the AI what Mohammed likes playing with. 
Now bearing in mind that variations of this technology is used in everything from legal discovery to customer service, the potential ramifications of race and gender bias are probably hurtling through your mind.
So now you might be thinking, “Well, I’m never using AI again! Humans only for me from now on!”. Of course, that leads right back to where the bias came from in the first place.
Can we find a better way? Is it possible to remove bias from Artificial Intelligence? We’ve been working on a different approach, which we’ll tell you all about in part 3.